

딥시크(DeepSeek)는 2023년에 설립된 중국의 인공지능(AI) 기업으로, 대규모 언어 모델(LLM)을 개발하고 있습니다.
2025년 1월 10일, DeepSeek는 DeepSeek-R1 모델을 기반으로 한 무료 AI 어시스턴트 앱을 iOS와 안드로이드용으로 출시하였으며, 이 앱은 미국 iOS 앱 스토어에서 ChatGPT를 제치고 인기차트 1순위에 올랐습니다. 그만큼 현재 반응이 뜨겁습니다.

왜 이렇게 난리일까?
딥시크는 저비용의 AI 솔루션을 제공함으로써, 기존의 AI 시장 구조를 변화시키고 있습니다.
특히 미국의 대형 AI 기업들에게 도전장을 내밀며, 글로벌 AI 시장에서 중요한 역할을 하고 있습니다.
딥시크는 비용 효율성과 오픈 소스 모델을 통해 AI 기술의 접근성을 높여, 다양한 기업과 연구자들에게 유용한 도구로 자리잡고 있습니다.
특히 Chat GPT와 비교를 하고 있는데, Chat GPT는 애초에 모델을 크게 만들어 성능을 좋게 만드는 전략을 펼쳐왔습니다.
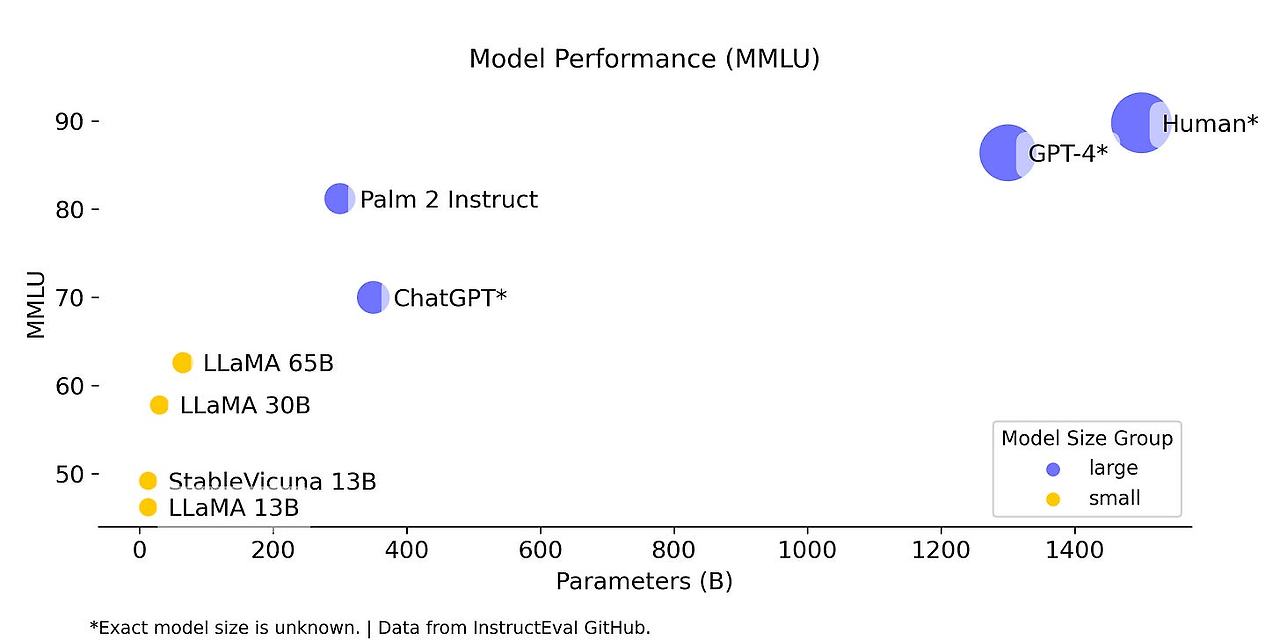
이 말도 안 되는 사이즈의 모델을 훈련하기 위해서 그 동안 GPU가 많이 필요할 수 밖에 없었습니다.
Open AI는 이대로 계속 가면 가장 인간에 가까운 모델이 탄생할 것이라고 생각했을 것입니다.
하지만 딥시크는 기존의 대규모 컴퓨팅 파워에 의존하는 접근 방식에 도전장을 내밀고 있습니다.
얼마나 리소스를 적게 쓸까요?
딥시크(DeepSeek)는 ChatGPT와 비교했을 때 상당히 적은 리소스를 사용하는 것으로 알려져 있습니다.
딥시크는 약 2,000개의 칩을 사용하는 반면, ChatGPT는 16,000개 이상의 칩을 사용합니다.
이는 딥시크가 ChatGPT에 비해 약 87.5% 적은 하드웨어 리소스를 사용한다는 것을 의미합니다.
리소스가 적게 사용되다 보니, OpenAI가 모델 훈련에 수천만 달러를 투자한 것과 달리 딥시크는 단 550만 달러로 AI 모델을 개발했다고 주장하고 있습니다.
그런데 성능이 비슷해?
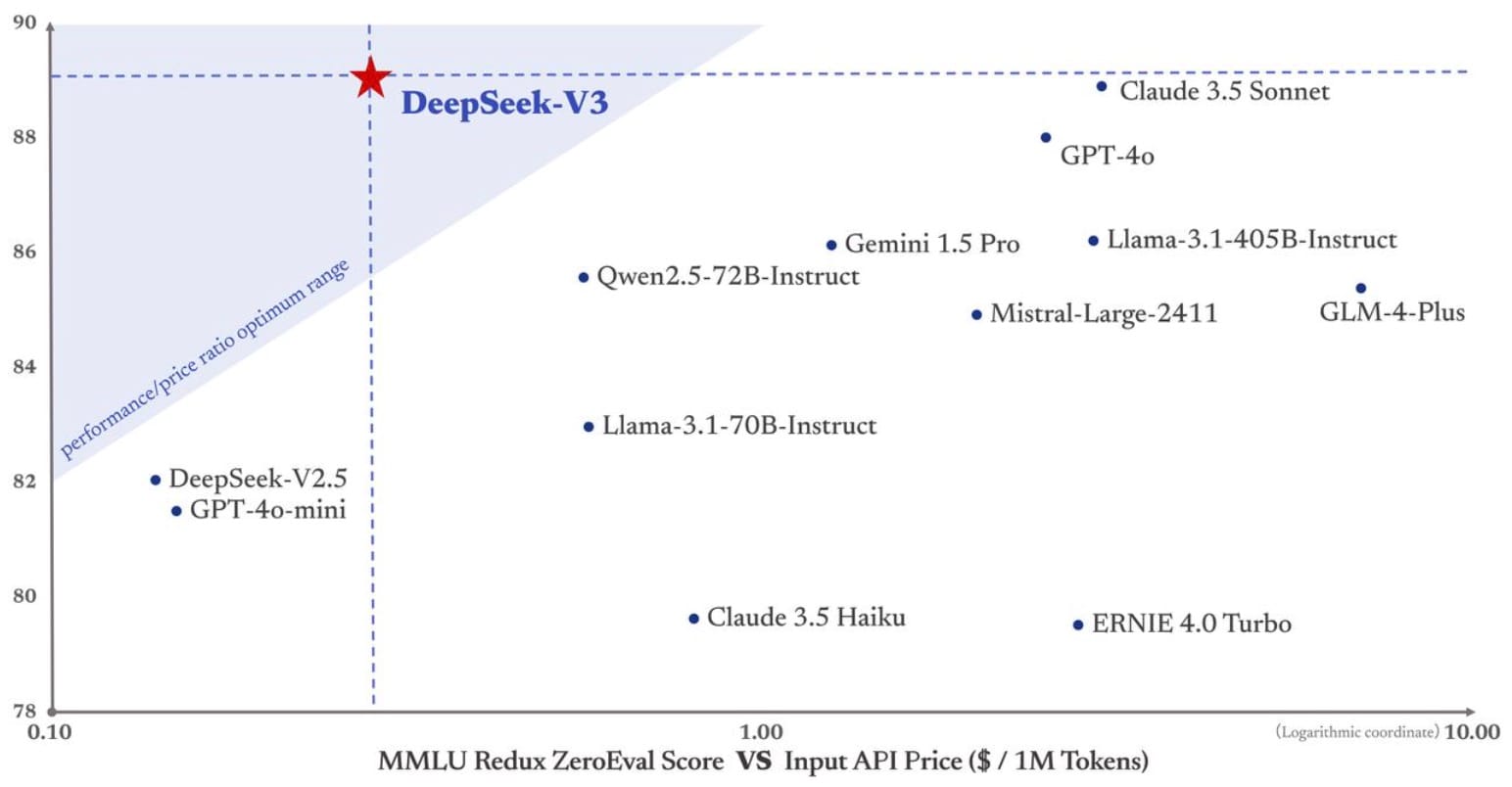
딥시크 DeepSeek에서 제공하는 자료에 따르면 OpenAI-o1-1217과 비슷한 성능을 내는 것으로 보여집니다.
OpenAI는 모델 사이즈를 공개하지 않는 정책을 가지기 때문에 정확한 모델 사이즈를 알 수는 없지만, DeepSeek-R1의 사이즈가 훨씬 적은 것으로 알려져 있습니다.

한 자료에서 보면 리소스 대비 성능이 압도적으로 높은 것으로 알 수 있습니다.
어떻게 했을까?
딥시크는 혁신적인 아키텍처를 제시했습니다.
전체적으로 저비용으로 학습을 하기 위해서 연구를 했던 노력이 느껴집니다.
- Mixture of Experts (MoE)
- 671억 개의 총 파라미터 중 각 작업마다 37억 개만 활성화됩니다. 이를 통해서 대규모 모델 성을 유지하면서 계산 비용을 절감했습니다.
- Multi-Head Latent Attention (MLA)
- 키-값(KV) 벡터를 저차원 잠재 공간으로 압축하여 메모리 사용량을 줄이고 추론 속도를 높였습니다
- FP8 혼합 정밀도 학습
- 8비트 부동소수점(FP8) 정밀도를 사용하여 GPU 메모리 사용량과 계산 비용을 절반으로 줄였습니다.
- 기존에는 FP32(32비트 부동소수점)와 FP16(16비트 부동소수점)을 조합해서 사용했습니다.
중국 모델.. 믿을만한가..?
사실 중국 AI 기술은 이전부터 두각을 드러내고 있었습니다.
AI 모델 개발은 데이터가 굉장히 중요한데, 나라 특성상 데이터를 쉽게 사용할 수 있는 구조라 좋은 모델들이 발표되고 있었습니다.
그런데 미국에 비해서는 두각을 드러내지 못 했죠.
그 이유는 아무래도 미국에서 GPU를 구하기 어렵기 때문일 것입니다.
따라서 딥시크 개발진들은 어떻게 하면 적은 GPU로 좋은 모델을 만들어낼 수 있을까? 를 고민했던 것 같습니다.
저도 중국에서 개발한 모델이다 보니, 의심들 수 있습니다.
그런데 이 모델은 오픈 소스로 공개되어 있고, 어디서나 검증해볼 수 있습니다.
(그만큼 자신이 있다는 의미인 것 같습니다.)
https://github.com/deepseek-ai
DeepSeek
DeepSeek has 16 repositories available. Follow their code on GitHub.
github.com
정리
딥시크의 등장으로 NVIDIA의 주가가 많이 떨어졌습니다.
지금 GPU가 부족해서 사고 싶어도 못 샀는데, 딥시크 모델을 활용한다면 구하기 어려운 GPU가 많이 필요하지 않기 때문입니다.
그만큼 현재 딥시크의 영향력이 큰데요.
AI 업계에서는 어떨까요? 저는 도화선에 불을 붙였다고 생각합니다.
현재 LLM 발전의 한계는 많은 GPU가 필요하다는 것이었습니다. 따라서 대부분의 대기업에서만 LLM 서비스를 할 수 있었는데요.
이제는 스타트업에서도 얼마든지 도전할 수 있을 것으로 보입니다.
또한 미국이 지금 자존심이 많이 상해있는 상태일텐데요. ^^
앞으로 미국의 행보가, 그리고 앞으로의 AI의 발전 속도가 궁금합니다.
'AI' 카테고리의 다른 글
| [D/L] CNN 이란? (feat. DACON) (0) | 2022.01.16 |
|---|