

맵리듀스와 스파크가 아주 유연하고 강력한 프레임워크이긴하지만, 이를 사용하려면 개발/배포/운영에 익숙해야한다. 하지만 대부분의 분석 기법은 SQL을 기반으로 하며, 복잡한 절차없이 분석 작업이 선호될 때가 있다.
그래서 하둡에 저장되는 데이터를 SQL과 비슷한 인터페이스로 사용할 수 있게 해주는 도구를 들이 생겨났다. 이들은 내부적으로 맵리듀스나 스파크를 근간으로하지만, 독자적인 연산 엔진을 갖춘 것도 있다. 각 엔진은 데이터를 쿼리하거나 대량 데이터를 저장하는 데 중점을 둔다.
Hive
하둡에 사용되는 데이터 웨어하우징 기술이다. HDFS에 저장된 정형 데이터를 하이브QL로 쿼리할 수 있게 만든 최초의 기술이다.
이는 ETL, 대용량 데이터 처리, 오프라인 배치 작업, 보고서 데이터 생성 등에 적합하다.
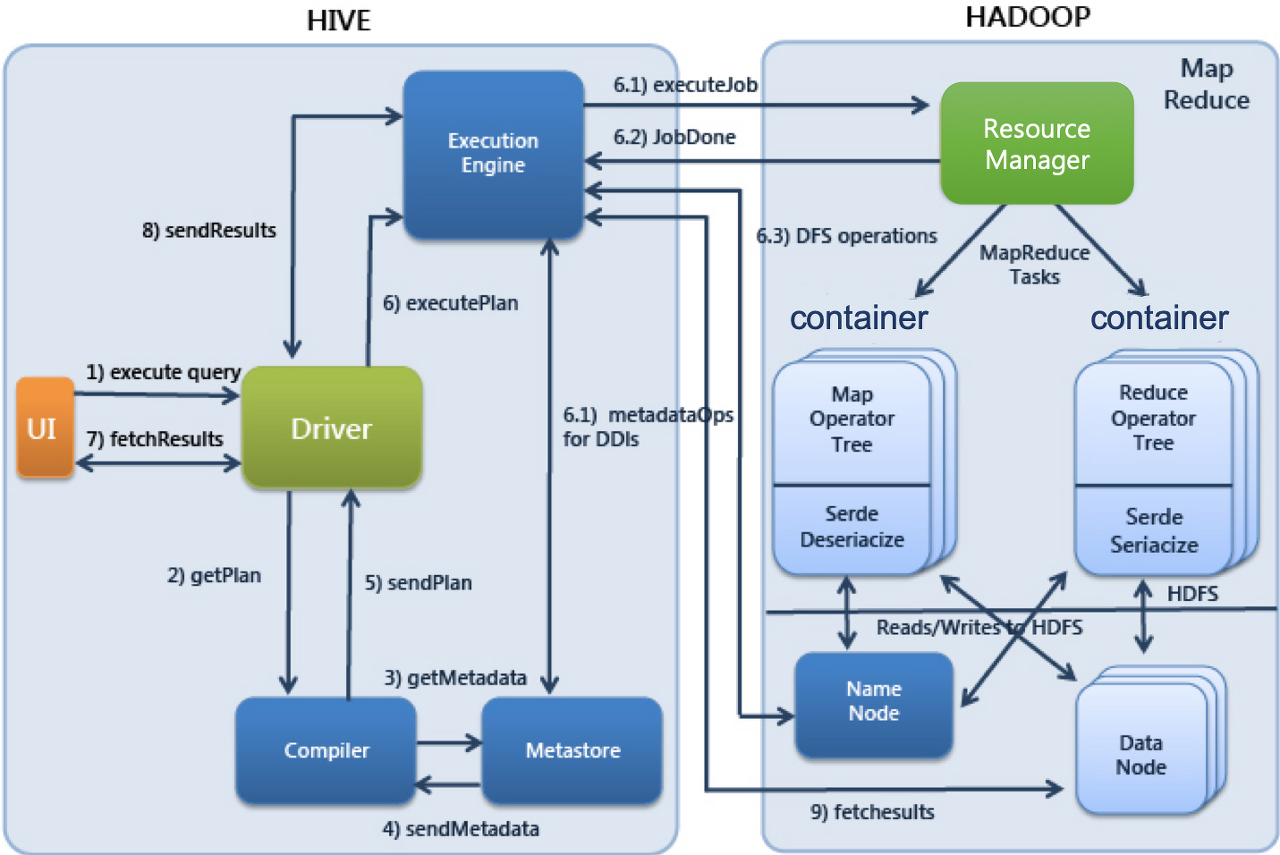
1. HiveQL 문을 Driver가 받고, 메타스토어의 정보를 활용하여 적합한 형태로 컴파일
2. 컴파일된 SQL을 실행 엔진으로 실행
3. 리소스 매니저가 클러스터 자원을 적절히 활용하여 실행
4. 원천 데이터는 HDFS를 활용
5. 결과를 사용자에게 변환

Hive Services
하이브는 사용자 쿼리를 파싱하고, 최적화해서 하나 이상의 연쇄 배치 연산으로 컴파일하며 이를 클러스터에서 실행한다.
- HiveServer2: 클라이언트에서 쿼리를 받는 쿼리서버, 다중 동시 접속을 지원하며 주키퍼를 통해 일관성을 보장한다.
- Hive Driver: HiveQL의 상태를 확인하고, 쿼리를 다루기 위한 세션을 생성한다.
- Metastore: HiveQL에 사용되는 데이터베이스와 테이블 정보를 가지고 있는 메타스토어 서버
- Hive Compiler: 메타스토어의 메타데이터를 활용하여 서로 다른 쿼리 블록과 쿼리 표현식에 대해 의미 분석 및 유형 검사를 수행하고, 실행 계획을 생성한다.
- Optimizer: 실행 계획의 작업들을 분산하여 연산의 효율성과 확장성을 향상시킨다.
Processing & Resource Management
다수의 연쇄 배치 연산 작업을 받아 다수의 워커를 통해 연산 작업을 실행한다. 이런 연산은 보통 맵리듀스 작업으로 실행되지만, Apache Tez나 Spark를 실행 엔진으로 사용할 수도 있다.
Impala
대규모 병렬 처리 엔진으로서, 하둡이나 클라우드 스토리지에 저장된 대용량 데이터셋에 대한 고속, 대화형 SQL 쿼리를 목적으로 설계되었다. 이를 통해 데이터 분석 업무에서 원하는 데이터를 빠르고, 쉽게 얻을 수 있다.
속도와 효율에 초점을 맞추므로 자체 분산 Query Engine을 사용한다. Impala에서는 데이터가 분산 연산자 트리를 스트림으로 통과하면서 처리된다.
텍스트 파일, HBase 테이블, Avro 등 다양한 데이터 소스를 지원한다.

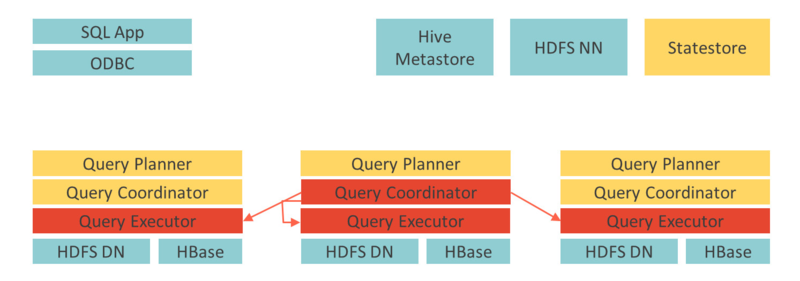

프로세스
- 클라이언트에서 쿼리를 전송할 워커 프로세스(Impala 데몬)를 선택한다. 해당 Demon은 코디네이터 노드라고 명명한다. 이 노드는 프래그먼트(분산 쿼리 계획의 일부)를 다른 데몬에게 전송
- 전송받은 나머지 데몬은 프래그먼트에 들어있는 연산자에 따라 연산을 수행한다. 각 데몬은 로컬에 있는 데이터에 대해 쿼리를 수행한다. 필요하다면 데몬끼리 데이터를 서로 교환한다. (분산 실행)
- 작업을 마치면 결과를 코디네이터로 스트리밍하고, 코디네이터는 최종 집계와 연산을 수행한 후 클라이언트에 스티리밍한다.
Hive vs Impala
Hive: Java로 구현, Hive SQL을 사용, 배치성 작업, ETL 유형의 대량 데이터에 대한 장기적/안정적인 일괄 처리 작업에 적합
Impala: C++로 구현, 표준 SQL을 사용, 실시간성 작업, 데이터 분석시 쉽고 간단하게 데이터를 얻는 작업에 적합
Presto
Presto는 분산 SQL 쿼리 엔진으로 Impala와 비슷한 특징들을 가지고 있다. 즉, 표준 SQL을 지원하며 데이터 분석가와 개발자가 매우 쉽게 사용할 수 있도록 개발되었다.
페타바이트 급의 대규모 데이터를 처리하기 위해서는 Presto를 사용하는 것이 적합하다. 또한 ETL없이 바로 스토리지에 접근할 수 있는 장점도 있다. 다만 HDFS에 대한 지원은 Impala에 비해 부족하다.
Hive, Cassandra, RDB, AWS S3 등 다양한 소스로부터 데이터를 읽어올 수 있다.
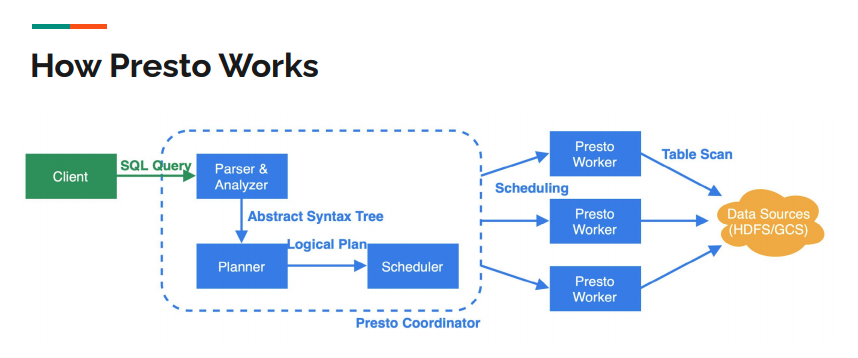
프로세스
- Parser: 클라이언트에게 쿼리를 전달받고, Metadata API와 연결하여 메타 데이터 정보를 가져옴
- Planner: 전달받은 쿼리가 작동하도록 쿼리 플랜을 작성한다.
- Scheduler: Worker가 일을 수행하게 끔 작업을 전달한다.
- Worker: Data stream API를 가져와 다수의 데이터 소스에서 쿼리가 작동하도록 작업을 수행한다. 이 작업은 Memory 상에서 수행되며, 스토리지에 저장되지 않는다. 이로 인해 컴퓨팅과 스토리지가 별도로 수행된다.
Top 5 reasons Presto is the foundation of the data analytics
최근 Presto는 데이터 분야에서 핫한 입지를 가지고 있다. 아래 자료에서는 다음과 같이 5가지 이유를 들고 있고, 이를 공유하고자 한다.
- Easier integration with ecosystem
기존의 진행 중인 데이터 시스템을 수정할 필요 없이 기존의 생태계와 원활하게 통합되도록 설계되었으며 클라우드 환경에 매우 적합하다. 게다가 추가 컴퓨팅 계층을 통해 더 빠른 분석이 가능해졌다. - Unified SQL interface
Presto는 표준 SQL을 지원하고, 많은 데이터 분석가들이 SQL에 익숙하다. - Performance
Impala와 같은 BI 쿼리는 대용량 데이터 처리에 적합하지 않고, Hive와 Spark가 대용량 데이터 처리에 적합하나 BI 쿼리와는 적합하지 않다.
Presto는 코드 생성, 인메모리 처리 및 파이프라인 실행과 같은 주요 기능과 고성능을 위해 구축되었으며 대용량 처리에 좋은 성능을 보여준다. - Query Federation
모든 데이터 소스를 추상화하는 단일 통합 SQL 언어를 제공한다. 이는 사용자가 기본 시스템의 연결 및 SQL 언어를 이해할 필요가 없는 강력한 기능이다. - Design suitable for cloud
컴퓨팅과 스토리지가 별도로 수행되는 설계는 클라우드 환경에서 운영되기 매우 편리하다. Presto 클러스터는 데이터를 저장하지 않기 때문에 데이터 손실 없이 자동 확장될 수 있다.
스토리지와 컴퓨팅이 분리되지 않는다면 블랙 프라이데이와 같이 트래픽이 많은 기간에 컴퓨팅의 확장이 필요할 때 스토리지가 추가로 필요하거나 스토리지의 확장이 필요할 때 컴퓨팅의 확징이 필요할 수 있다. 이러한 불필요한 지출을 줄일 수 있다
https://ahana.io/blog/top-5-reasons-presto-is-the-foundation-of-the-data-analytics-stack/
Top 5 reasons Presto is the foundation of the data analytics stack and why you should use Presto
Data platform teams are increasingly using the federated SQL query engine PrestoDB to run such analytics for a variety of use cases across a wide range of data lakes and databases in-place, without the need to move data. Here's a look at some important cha
ahana.io
해당 내용은 다음 책을 참고했습니다.
엔터프라이즈 데이터 플랫폼 구축 - YES24
자체 시스템부터 클라우드까지 엔터프라이즈 하둡과 빅데이터 플랫폼 운영, 구축, 설계의 모든 것빅데이터 기술에 대한 정보는 넘쳐나지만 이 모든 기술을 매끄럽게 연결해서 완벽한 엔터프라
www.yes24.com
'Engineering 💻 > Hadoop' 카테고리의 다른 글
| [Hadoop] Spark 동작 단계 (0) | 2022.01.18 |
|---|---|
| [Hadoop] 오케스트레이션 (feat. Oozie, Airflow) (0) | 2022.01.13 |
| [Hadoop] 연산 프레임워크 (feat. MapReduce, Spark, Flink) (0) | 2022.01.11 |
| [Hadoop] 핵심 컴포넌트 (feat. HDFS, YARN, ZooKeeper, Hive Metastore) (0) | 2022.01.11 |
| [DW] 데이터 웨어하우스 기초 (0) | 2022.01.10 |