
데이터 웨어하우스란?
다양한 시스템에서 데이터를 공통의 형식으로 추출하여 적재된 분석용 중앙 데이터베이스를 의미한다.
- 사용자의 의사결정에 도움을 주기 위해 설계되었다.
- 만약 분석을 위해 필요한 큰 쿼리들을 시스템에서 사용하는 데이터베이스에 직접 요청한다면 부하로 인해 서비스에 영향을 미칠 수 있다.
Ex. 분석을 위해서 1년 간의 고객데이터를 운영되고 있는 데이터베이스에 요청하게 된다면 과도한 트래픽에 의해서 장애가 날 수 있다.
데이터 웨어하우스의 성격
주제지향성
데이터 웨어하우스는 구축 전 사용 목적이 정의되어있다. DW의 데이터들은 이용자에게 이해하기 쉬운 형태로 제공된다.
통합성
여러 소스의 데이터를 통합해서 분석이 가능하다. (데이터 속성의 이름, 단위 등의 일관성을 통합한다.)
시계열성
시간에 따라서 쌓인 데이터를 분석한다.
데이터 웨어하우스의 아키텍쳐
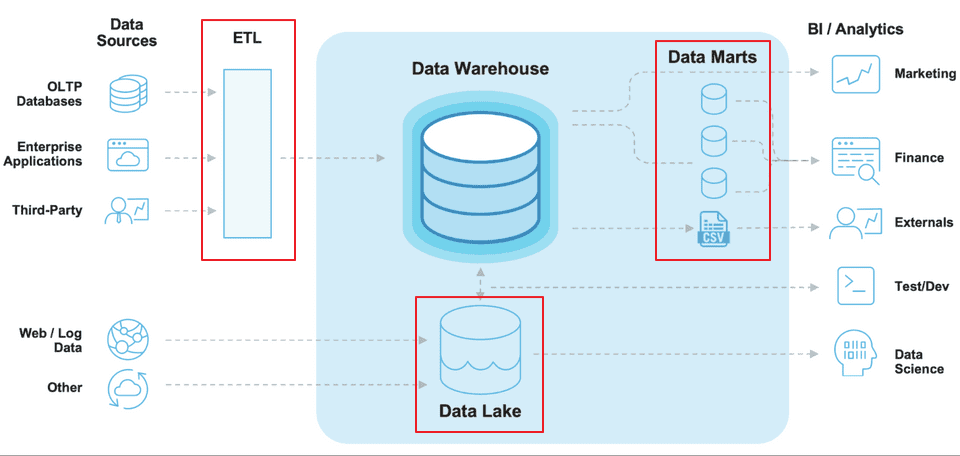
ETL/ELT
- 데이터 웨어하우스 구축시 운영 시스템에서 데이터를 추출하여 가공(변환, 정제)한 후 적재하는 과정을 말한다.
여기서 말하는 데이터 변환에는 필터링, 정렬, 집계, 데이터 조인, 데이터 정리, 중복 제거 및 데이터 유효성 검사 등의 다양한 작업이 포함된다. - 빅데이터를 처리하기 위한 실시간 데이터 처리, 수집, 통합 성능이 부족하다. 따라서 더 나은 접근법인 ELT라는 대안이 나타났다.
데이터 레이크 (Data Lake)
모든 가공되지 않은 다양한 데이터를 모아둔 총체적이고 큰 규모의 중앙 레포지토리이다. 빅데이터 분석에서 필요한 비정형 데이터까지 수집하고 분석하는 수요를 충족시킬 수 있다.
데이터 마트 (Data Mart)
금융, 마케팅 등의 특정 팀 또는 사업 단위의 요구를 충족시키는 sub 데이터 웨어하우스이다. 불필요하게 많은 양의 데이터를 조회할 필요가 없기 때문에 데이터 조회 성능이 향상된다.
데이터 웨어하우스 서비스
Snowflake
신개념 데이터 클라우드 IT기업.
- 특정 공간(Silos)에 국한되는 별도의 저장소가 존재하지 않고, 데이터로 클라우드를 구성한다. 즉, 폴더/지역같은 저장소 개념이 아닌 데이터 그 자체의 자유로운 Snowflake(데이터) 공유가 가능해지는 것이다.
- 데이터에 직접 접근할 수 있기 때문에 불필요한 동일 데이터를 복제할 필요가 없다. 예를들어 공유폴더의 파일을 개인의 컴퓨터에 다운로드할 필요가 없는 것이다. 이로 인해 데이터는 항상 최신상태로 유지된다.
Apache Hive
하둡에서 정형화된 데이터를 처리하기 위한 데이터 웨어하우징용 솔루션
- 아파치 HDFS(Hadoop Distributed File System), 아파치 HBase와 같은 데이터 저장 시스템에 저장되어 있는 대용량 데이터 집합을 분석
- 쿼리를 빠르게 하기 위해 비트맵 인덱스를 포함하여 인덱스 기능 제공
- 미리 스키마를 정의하고, 그 틀에 맞고 데이터를 입력하는 기존의 RDB와 다르게 데이터를 저장하고 거기에 스키마를 입히는 메타스토어 기능 제공
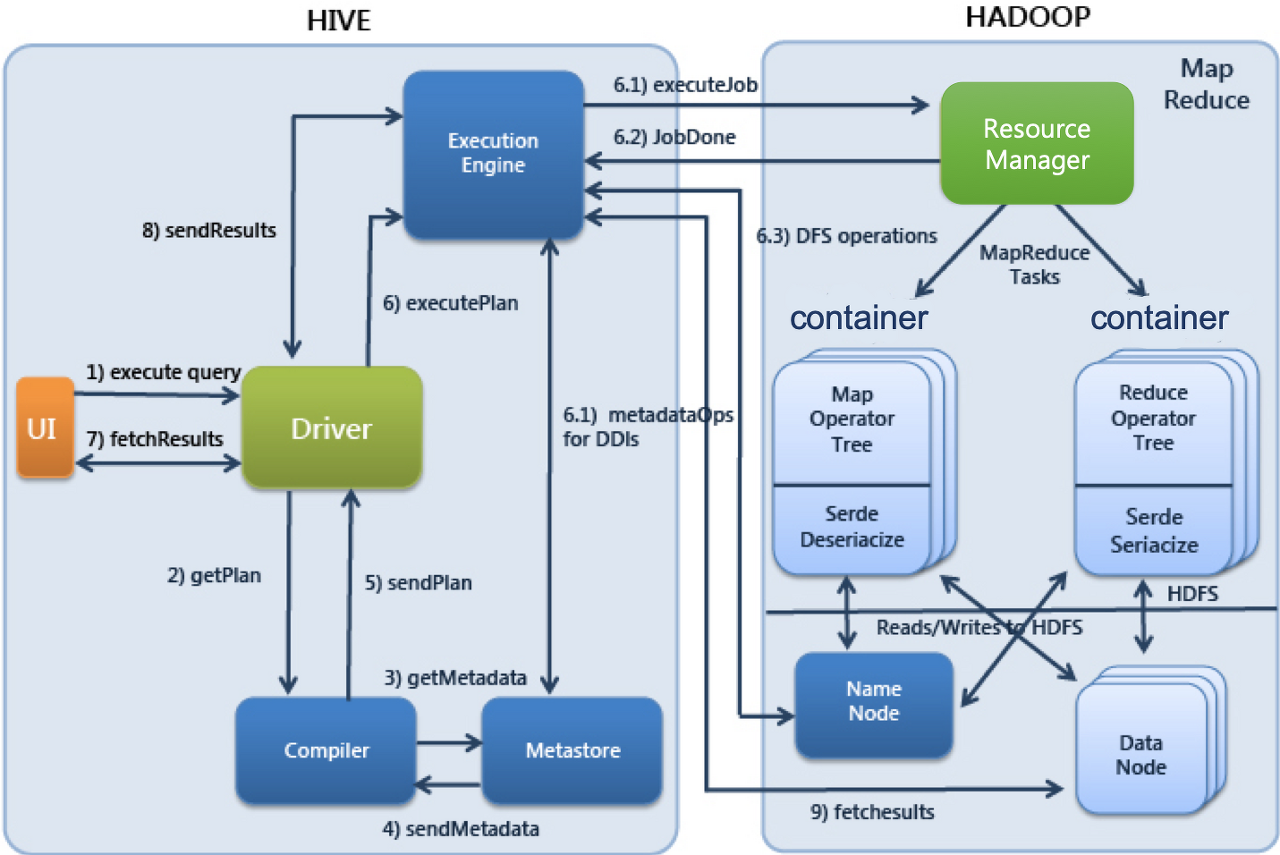
하이브 실행순서
Hive-1. 사용자가 제출한 SQL문을 드라이버가 컴파일러에 요청
Hive-2. 메타스토어의 정보를 이용해 적합한 형태로 컴파일
Hive-3. 컴파일된 SQL을 실행엔진으로 실행
Hadoop-1. 리소스 매니저가 클러스터의 자원을 적절히 활용하여 실행
Hadoop-2. 실행 중 사용하는 원천데이터는 HDFS 등의 저장장치를 이용
Hive-4. 실행결과 반환
AWS RedShift
AWS에서 제공하는 데이터 웨어하우스 엔진.
- PostgreSQL을 기반으로 한다. 따라서 표준 SQL을 통한 데이터 처리 지원
- 칼럼 기반으로 압축하여 데이터를 저장하여 데이터의 빠른 처리를 지원
Google BigQuery
확장성이 뛰어난 구글의 기업용 서버리스 데이터 웨어하우스
- 스토리지와 컴퓨팅이 분리되어 있기 때문에 웨어하우스 용량을 원하는 대로 계획할 수 있는 탄력적인 확장성
반응형
'Engineering 💻 > Hadoop' 카테고리의 다른 글
| [Hadoop] Spark 동작 단계 (0) | 2022.01.18 |
|---|---|
| [Hadoop] 오케스트레이션 (feat. Oozie, Airflow) (0) | 2022.01.13 |
| [Hadooop] 분석용 SQL 엔진 (feat. Hive, Impala, Presto) (0) | 2022.01.12 |
| [Hadoop] 연산 프레임워크 (feat. MapReduce, Spark, Flink) (0) | 2022.01.11 |
| [Hadoop] 핵심 컴포넌트 (feat. HDFS, YARN, ZooKeeper, Hive Metastore) (0) | 2022.01.11 |